トップページ - 翻訳ドキュメント - オラクルデータベースの復旧
原文:http://examples.oreilly.com/unixbr/oracle.html
訳注:原文のHTMLはかなりおかしな事になっていますが、その辺りは適宜修正しています。恐らく Oracle7 向けの資料だと思います。今ではやや古い感も否めないのですが、参考にはなるかと思います。
2005/12/08 全体的に見直し。意味が変わったような箇所はないはずです。
ソーシャルブックマーク:
![]()
![]()
![]()
Oracle データベースの復旧
Oracle データベースは互いに関連し合う複数のパーツから構成されているため、データベース等の復旧は消去法を用いて行われます。まずどの部分が正常動作しているかを識別し、その後、正常動作していない部分を復旧します。以下の復旧ガイドは、バックアップ方法に依存しないその判断方法と作業手順を示しており、フローチャートとその中の各要素に対応する番号が付けられた手順で構成されています。
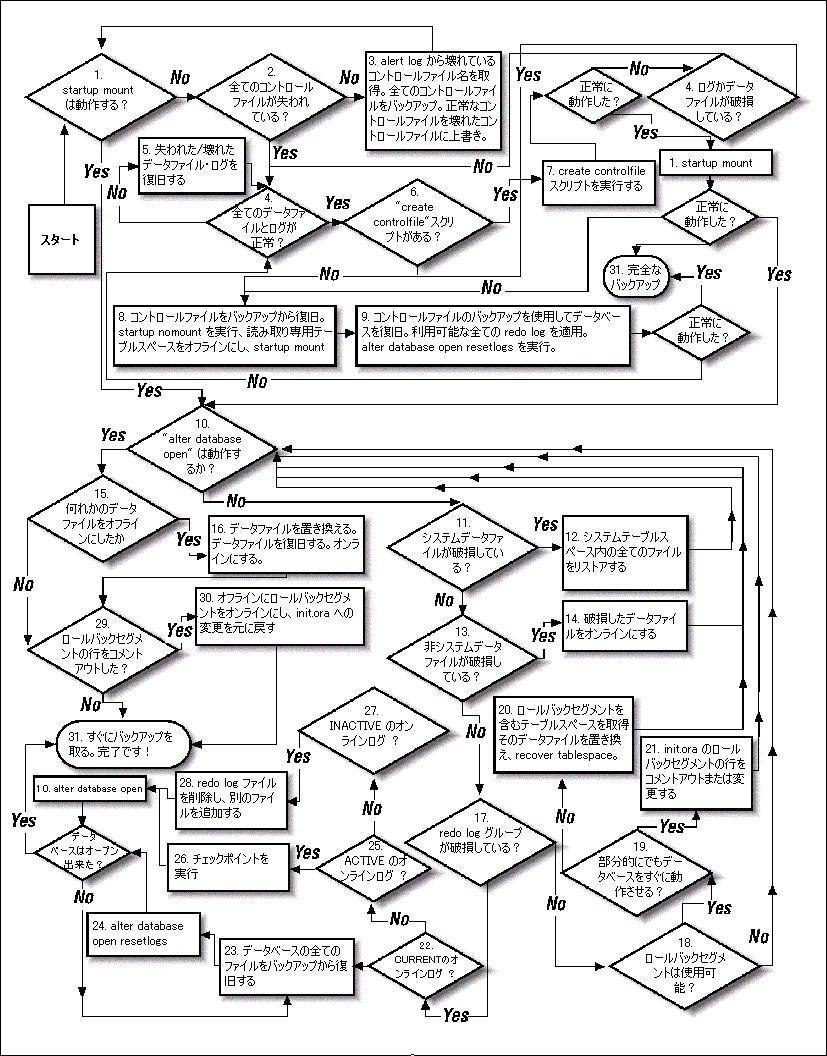
オラクルデータベースの状態を確認する最初のステップは、マウントを試みることです。なぜこれがうまく働くのかと言うと、データベースをオープンしないマウントは、コントロールファイルは読み込みますがデータファイルはオープンしないからです。コントロールファイルがミラーリングされている場合、オラクルはinitORACLE_SID.ora ファイル内にリストされている各コントロールファイルを開こうとします。その何れかのファイルが破損している場合、マウントは失敗します。
データベースをマウントするには、単純に svrmgrl を実行してデータベースに接続し、startup mount と入力します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > startup mount; Statement processed.
成功した場合、以下のような内容が出力されます。
SVRMGR > startup mount; ORACLE instance started. Total System Global Area 5130648 bytes Fixed Size 44924 bytes Variable Size 4151836 bytes Database Buffers 409600 bytes Redo Buffers 524288 bytes Database mounted.
データベースのマウントに成功した場合、ステップ 10 に進んで下さい。
データベースのマウントに失敗した場合、以下のような内容が出力されます。
SVRMGR > startup mount; Total System Global Area 5130648 bytes Fixed Size 44924 bytes Variable Size 4151836 bytes Database Buffer to s 409600 bytes Redo Buffers 524288 bytes ORACLE instance started. ORA-00205: error in identifying controlfile, check alert log for more info
データベースのマウントに失敗した場合、ステップ 2 に進んで下さい。
データベースのマウントに失敗してもパニックになってはいけません。コントロールファイルは、ミラーリングされていれば簡単に復元できますし、必要ならゼロから再構築することも出来ます。第一の重要な情報は、ひとつ以上のコントロールファイルが失われているかどうかです。
残念ながら、オラクルが最初の失敗でマウントを異常終了しているので、ひとつか二つか、あるいは全てのコントロールファイルが失われていると考えられます。しかしこの時点では、先頭の失われたファイルだけが分かっている状態です。次の行動を起こす前に、問題の深刻度を見極めなければいけません。そのために若干の調査を行います。
最初に、全てのコントロールファイルの名前を調べます。それにはconfigORACLE_SID.ora ファイルを開き、その中のcontrol files を調べます。以下のような内容です。
control_files = (/db/Oracle/a/oradata/crash/control01.ctl, /db/Oracle/b/oradata/crash/control02.ctl, /db/Oracle/c/oradata/crash/control03.ctl)
オラクルが不平を言っているコントロールファイルの名前を知ることも重要です。それには、alert log の中から control file: という語句を探します。alert log は configinstance.ora ファイル内の background_dump_dest で指定されている場所にあります。そのディレクトリ内に alert_ORACLE_SID.log という名前のファイルがあり、その中に以下のようなエラーが記録されているはずです。
Sat Feb 21 13:46:19 1998 alter database mount exclusive Sat Feb 21 13:46:20 1998 ORA-00202: controlfile: '/db/a/oradata/crash/control01.ctl' ORA-27037: unable to obtain file status SVR4 Error: 2: No such file or directory
警告! 以降の手順の一部では、壊れたコントロールファイルを上書きするように指示しています。どのファイルが必要になるかを事前に知ることは出来ないため、以降の手順を実行する前に全てのコントロールファイルのコピーをバックアップして下さい。これにより、これをやっておかないと出来ない"やり直し"も可能になります。(同様にオンライン redo log もコピーして下さい。)
全てのコントロールファイルの名前と破損したファイルの名前とが分かれば、問題の深刻度を見極めるのは簡単です。そのためには各コントロールファイルのサイズと更新時刻とを比較します。(セサミストリートのゲーム"仲間はずれはどれ?"を思い出して下さい?) 以下のシナリオではコントロールファイルが 3箇所にミラーリングされていると仮定しています(これはごく一般的なケースと言えます)。取り得るシナリオは以下の通りです。
破損したコントロールファイルは失われているが、少なくともひとつ以上の他のコントロールファイルは存在している
オラクルが不平を言っているファイルだけが失われている場合、修復は簡単です。
この場合、ステップ 3 に進んで下さい。
破損したファイルは失われていないが、壊れている
これはファイルが壊れていると断定するのが困難なため、恐らく最も混乱するパターンです。この場合にするべきことは、個人的な選択になります。先へ進む前に、全てのコントロールファイルのコピーをバックアップして下さい。バックアップが完了した後、それらの異なるファイルを使って"ごまかし(shell game)"に挑戦します。この"ごまかし"とは、三つのコントロールファイルからひとつを選び、それをその他の二つのファイルに上書きすることです。その後、データベースのマウントを再試行して下さい。この"ごまかし"に付いてはステップ 3 に書かれています。
しかしながら、もし全てのオンライン redo log が存在しているなら、ステップ 6 とステップ 7 とに記述されている "create controlfile" スクリプトを実行する方がこの時点ではより簡単でしょう。これは全ての場所にコントロールファイルを自動的に再構築します。(その前に、全てのデータファイルとログファイルが存在していることを確認するため、ステップ 4 とステップ 5 とに従って下さい。)
"create controlfile" スクリプトを用いてコントロールファイルを再構築するには、ステップ 4 〜 7 に進んで下さい。
全てのコントロールファイルが失われている。または全てのファイルのサイズや更新時刻が異なる。
全てのコントロールファイルが壊れているか失われている場合、それらを再構築するか、データベース全体をリストアしなければいけません。運がよければ、あなたのバックアップシステムは定期的にbackup control file to trace コマンドを実行しています。(このコマンドの出力は、コントロールファイルを再構築する SQL スクリプトになっています。)
backup control file to trace コマンドが実行されていればステップ 4 〜 7へ進んで下さい。実行されていなければステップ 8 へ進んで下さい。
オラクルが不平を言っているファイルが失われているか、他のファイルとは異なる日付や時刻になっているように見える場合、これは非常に簡単です。単純に、ミラーリングされたコントロールファイルのコピーのひとつを破損したコントロールファイルの場所に同じ名前で上書きします(この手順の詳細は後述します)。これを実行した後、再度データベースのマウントを試みて下さい。
警告! これらを上書きする前に、全てのコントロールファイルのコピーがバックアップされている事を確認して下さい!
最初にするべきことは、破損したコントロールファイルの名前を知ることです。繰り返しになりますが、これは比較的簡単です。alert log から以下のような部分を探して下さい。
Sat Feb 21 13:46:19 1998 alter database mount exclusive Sat Feb 21 13:46:20 1998 ORA-00202: controlfile: '/db/a/oradata/crash/control01.ctl' ORA-27037: unable to obtain file status SVR4 Error: 2: No such file or directory
コントロールファイルをコピーする前に、全てのコントロールファイルのバックアップを行って下さい。次のステップでは正常だと分かっているコントロールファイルを破損したコントロールファイルの場所にコピーします。
これを実行した後、ステップ 1 に戻り、再び startup mount を試みて下さい。
"でも、私は正常なコントロールファイルを持ってません!"
残っているコントロールファイルの日付やサイズが異なっている場合のように、正常なコントロールファイルが分からない事も有り得ます。このような場合には "create controlfile" スクリプトを利用するのがおそらく最も良い方法です。
create controlfile スクリプトを使用するには、ステップ 4 〜 7 へ進んで下さい。
それが不可能、または可能性が低い場合、以下の手順を試みて下さい。まずは、全てのコントロールファイルをバックアップして下さい。次に、一度に1ファイルずつ各コントロールファイルをその他のコントロールファイルの場所にコピーしてみます。ただし、オラクルが不平を言っているファイルは明らかに破損しているので除きます。
各コントロールファイルを他の全ての場所にコピーする毎に、ステップ 1 へ戻って下さい。
例えば、次の三つのコントロールファイルがあると仮定します:/a/control1.ctl 、/b/control2.ctl 、/c/control3.ctl。そしてalert log は、/c/control3.ctl が破損していることを告げています。ここで /a/control1.ctl の更新時刻と/b/control2.ctl の更新時刻とが異なっていると、どれが正常なファイルなのかを知る方法がありません。この場合、以下の手順を試して下さい。
まず、全てのファイルのコピーをバックアップします。
$ cp /a/control1.ctl /a/control1.ctl.sav $ cp /b/control2.ctl /b/control2.ctl.sav $ cp /c/control3.ctl /c/control3.ctl.sav
次に、ひとつのファイルを他の全ての場所にコピーします。ただし control3.ctl は明らかに破損していることが分かっているので飛ばします。control1.ctl から始めてみましょう。
$ cp /a/control1.ctl /b/control2.ctl $ cp /a/control1.ctl /c/control3.ctl
では、startup mount を実行してみましょう。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > startup mount Sat Feb 21 15:43:21 1998 alter database mount exclusive Sat Feb 21 15:43:22 1998 ORA-00202: controlfile: '/a/control3.ctl' ORA-27037: unable to obtain file status
このエラーにより、今コピーしたファイルも破損している事が分かりました。では次のファイル、control2.ctl を試してみましょう。
$ cp /b/control2.ctl /a/control1.ctl $ cp /b/control2.ctl /a/control3.ctl
そして startup mount を実行してみて下さい。
SVRMGR > startup mount; ORACLE instance started. Total System Global Area 5130648 bytes Fixed Size 44924 bytes Variable Size 4151836 bytes Database Buffers 409600 bytes Redo Buffers 524288 bytes Database mounted.
どうやら control2.ctl は正常なコントロールファイルだったようです。
データベースのマウントに成功した後、ステップ 10 に進んで下さい。
ステップ 4 および 5 は、ステップ 6 を実行する前にのみ必要です。
ステップ 7 に書かれている "create controlfile" スクリプトは、全てのデータファイルとオンライン redo log とが適切な場所に存在している場合にのみうまく動作します。データファイルはメディアリカバリによってロールフォワード出来るのでバックアップからリストアされた古いバージョンでも構いませんが、オンライン redo log は最新かつ完全でなければなりません。
その理由は、再構築の処理がコントロールファイルを再構築する時に各データファイルを参照しているためです。各データファイルは、ある特定のオンライン redo log に対応する System Change Number (SCN) を持っています。データファイルが redo log よりも新しい SCN を持っている場合、コントロールファイルの再構築は異常終了するでしょう。
ひとつ以上のデータファイルまたは redo log が破損していると思われる場合、ステップ 5 に進んで下さい。逆にそれら全てが正常であると思われる場合、ステップ 6 に進んで下さい。
ひとつ以上のデータファイルかオンライン redo log かが確実に破損している場合、そのほかに破損したファイルがあるかどうかを確認するために、以下の手順に従って下さい(ここでのほんの少しの努力が、後々の大きなフラストレーションを解消してくれるでしょう)。 もし全てのデータファイルとオンライン redo log とが正常だという見込みがあるなら、もうひとつの選択肢として、このステップを飛ばし、コントロールファイルの再生成を試みることも出来ます(そこで失敗したとしても損害はありません)。 もし失敗した場合はこのステップに戻って下さい。十分に時間があるのなら、もう一度このステップを最初から実行して下さい。
ここでコントロールファイルの再生成を試みるなら、ステップ 6 に進んで下さい。
最初に調べることは、全てのデータファイルと redo log の場所です。これを調べるには、マウントして閉じられたデータベース上で以下のコマンドを実行します。
SVRMGR > connect internal; Connected. SVRMGR > select name from v$datafile; (出力例は下に) SVRMGR > select group#, member from v$logfile; (出力例は下に)
図 B はこれらのコマンドの出力例です。
SVRMGR > select name from v$datafile; NAME -------------------------------------------------------------------------------- /db/Oracle/a/oradata/crash/system01.dbf /db/Oracle/a/oradata/crash/rbs01.dbf /db/Oracle/a/oradata/crash/temp01.dbf /db/Oracle/a/oradata/crash/tools01.dbf /db/Oracle/a/oradata/crash/users01.dbf /db/Oracle/a/oradata/crash/test01.dbf 6 rows selected. SVRMGR > select group#, member from v$logfile; MEMBER -------------------------------------------------------------------------------- 1 /db/Oracle/a/oradata/crash/redocrash01.log 3 /db/Oracle/c/oradata/crash/redocrash03.log 2 /db/Oracle/b/oradata/crash/redocrash02.log 1 /db/Oracle/b/oradata/crash/redocrash01.log 2 /db/Oracle/a/oradata/crash/redocrash03.log 3 /db/Oracle/c/oradata/crash/redocrash02.log 6 rows selected. SVRMGR >
図 B: v$datafile の出力例と v$logfile の出力例
上記コマンドで表示された各ファイルを見ていきましょう。最初にデータファイルを見ます。各データファイルは、恐らく同じ更新時刻になっているか、もしかするとある更新時刻のグループと別の更新時刻のもうひとつのグループとが存在しているかもしれません。主に調べなければならない事は、失われたファイルまたは長さゼロのファイルがあるかどうかです。その他に調べるべきことは、最新の redo log よりも新しい更新時刻を持つファイルが存在するかどうかです。もしそのような状態のデータファイルがあるなら、バックアップからリストアしなければいけません。
redo log ファイルの場合は少々異なります。ひとつのロググループに含まれる各 redo log ファイルは同じ更新時刻でなければいけません。例えば上記のコマンド出力例では、/db/Oracle/a/oradata/crash/redocrash01.log と /db/Oracle/a/oradata/crash/redocrash01.log とがグループ 1 に含まれています。これらは同じ更新時刻とサイズでなければいけません。グループ 2 と 3 に関しても同様です。ここではいくつかのシナリオが考えられます。
ひとつまたは複数のロググループが、少なくともひとつの正常なログと破損したログとを含んでいる場合
これこそが redo log がミラーリングされる理由です! 正常な redo log を破損した redo log の場所にコピーして下さい。例えば、/db/Oracle/a/oradata/crash/redocrash01.log が失われていて /db/Oracle/a/oradata/crash/redocrash01.log が正常な場合、以下のコマンドを実行して下さい。
$ cp /db/Oracle/a/oradata/crash/redocrash01.log \ /db/Oracle/a/oradata/crash/redocrash01.log
少なくともひとつのロググループにおいて、それに含まれている全ての redo log が破損している場合
これは悪いケースです。ステップ 6 での "create controlfile" スクリプトには、全てのオンライン redo log が存在していることが必要です。たとえひとつでもロググループが完全に破損している場合、コントロールファイルを再構築することは出来ません。つまりここで唯一有効な選択肢は、ステップ 23・24 (データベース全体の完全な復旧と、その後のalter database open resetlogs コマンド)に進むことだけです。
警告! これは思い切ったステップです! 少なくともひとつのロググループ内の全ての メンバーが失われていることを良く確認して下さい。(上の例の場合、/db/Oracle/a/oradata/crash/redocrash01.log と /db/Oracle/a/oradata/crash/redocrash01.log とが破損しているなら、このデータベースは完全なリカバリが必要です。)
少なくともひとつのグループ内の全ての redo log が破損しており、なおかつコントロールファイルも破損している場合、ステップ 23・24 に進んで下さい。
redo log が全て正常で、全てのコントロールファイルが失われている場合、ステップ 6 に進んで下さい。
何か別の理由でデータベースをオープン出来ない場合、ステップ10に進んで下さい。
このステップの前に、ステップ 4 と 5 を実行していなければいけません。
svrmgrl の alter database backup control file to trace コマンドは、"create controlfile" を含むトレースファイルを生成します。このコマンドは cron で定期的に実行しておくべきです。このようなスクリプトが有効になっているかどうかを見つけるには、以下の指示に従って下さい。最初に見つけるべきことは、トレースファイルの出力先です。これは通常、 $ORACLE_HOME/dbs にある configinstance.ora 内の user_dump_dest の値によって指定されます。(一般的には $ORACLE_BASE/$ORACLE_SID/admin/udump です) 最初にそのディレクトリに cd を行い、次に CREATE CONTROLFILE を grep します。例:
$ cd $ORACLE_HOME/dbs; grep user_dump_dest configcrash.ora
user_dump_dest = /db/Oracle/admin/crash/udump
$ cd /db/Oracle/admin/crash/udump ; grep 'CREATE CONTROLFILE' * \
|awk -F: '{print $1}'|xargs ls -ltr
-rw-r----- 1 Oracle dba 3399 Oct 26 11:25 crash_ora_617.trc
-rw-r----- 1 Oracle dba 3399 Oct 26 11:25 crash_ora_617.trc
-rw-r----- 1 Oracle dba 1179 Oct 26 11:29 crash_ora_661.trc
図 C の例では、crash_ora_661.trc が "create controlfile" スクリプトを含む最新のファイルです。
create controlfile スクリプトが存在する場合、ステップ 7 に進んで下さい。create controlfile スクリプトが存在せず、なおかつ全てのコントロールファイルが失われている場合、ステップ 8 に進んで下さい。
まずはスクリプトを含むトレースファイルを探します。その手順はステップ 6 に書かれています。スクリプトを見つけたら、それを例えば rebuild.sql のような別の名前にコピーします。次にそのファイルを開き、# The following commands will create... という文言より上の部分と、SQL コマンド以降との全てを削除します。これによりファイルは図 D のような内容になっているはずです。
# The following commands will create a new controlfile and use it # to open the database. # Data used by the recovery manager will be lost. Additional logs may # be required for media recovery of offline data files. Use this # only if the current version of all online logs are available. STARTUP NOMOUNT CREATE CONTROLFILE REUSE DATABASE "CRASH" NORESETLOGS ARCHIVELOG MAXLOGFILES 32 MAXLOGMEMBERS 2 MAXDATAFILES 30 MAXINSTANCES 8 MAXLOGHISTORY 843 LOGFILE GROUP 1 '/db/a/oradata/crash/redocrash01.log' SIZE 500K, GROUP 2 '/db/b/oradata/crash/redocrash02.log' SIZE 500K, GROUP 3 '/db/c/oradata/crash/redocrash03.log' SIZE 500K DATAFILE '/db/a/oradata/crash/system01.dbf', '/db/a/oradata/crash/rbs01.dbf', '/db/a/oradata/crash/temp01.dbf', '/db/a/oradata/crash/tools01.dbf', '/db/a/oradata/crash/users01.dbf' ; # Recovery is required if any of the data files are restored backups, # or if the last shutdown was not normal or immediate. RECOVER DATABASE # All logs need archiving and a log switch is needed. ALTER SYSTEM ARCHIVE LOG ALL; # Database can now be opened normally. ALTER DATABASE OPEN; # Files in read only tablespaces are now named. ALTER DATABASE RENAME FILE 'MISSING00006' TO '/db/a/oradata/crash/test01.dbf'; # Online the files in read only tablespaces. ALTER TABLESPACE "TEST" ONLINE;
ファイルが上の例のようになっていれば、"STARTUP MOUNT" の直前に次の行を追加します。
connect internal;
この行を追加した後、マウントして閉じられたデータベース上で以下のコマンドを実行します。rebuild.sql は適切な名前に置き換えて下さい。
$ svrmgrl < rebuild.sql
全てのデータファイルとオンライン redo log とが適切な場所にあれば、このスクリプトは問題なく動作し、コントロールファイルを完全に再構築するでしょう。
このインスタンスのデータファイルの何れかが失われている場合はステップ 4 に戻って下さい。ただし、このインスタンスのオンライン redo log の何れかが破損しているか失われている場合、この選択肢はうまく行きません。 ステップ 8 に進んで下さい。
このステップは、ステップ 2 〜 7 に失敗した場合にのみ必要です。
この文書の他のところに書かれている忠告に従っているのなら、ここに来るのは唯一つのシナリオ -- 劇的な事故による全システムの損失 -- しかありません。ディスクドライブ(たとえ複数のディスクドライブでも)の損失は、コントロールファイルがミラーリングされていれば簡単に処置できます。たとえ全てのコントロールファイルが失われている場合でも、backup control file to trace コマンドを実行することで生成されるトレースファイルを使用すれば再構築することが出来ます。そのスクリプトがうまく動作しないのは、全てのオンラインロググループが失われている場合だけです。全てのミラーリングされたコントロールファイルと、全てのミラーリングされたロググループのメンバーとを失う場合とは、火事やその他の自然災害のような完全なシステム障害の場合でしょう。そのような場合には完全なデータベースリカバリの方ががより適切でしょう。
でも私はコントロールファイルやオンライン redo log をミラーリングしていませんでした。
以下のステップに従い、コントロールファイルをバックアップからリストアして下さい。データベースファイルも同様にリストアする必要があるかもしれません。これは、最新のデータファイルよりも古いコントロールファイルを使用することが出来ないためです(その場合オラクルは不平を言い、異常終了します)。 コントロールファイルがデータファイルより新しいことを確認するには、データベースのファイルを上書きせずに以下のステップを試み、何が起きるかを見ます。
コントロールファイルをバックアップからリストアする
この手順でまず最初にすることは、バックアップから最新のコントロールファイルを探してリストアすることです。これは backup control file to filename コマンドの実行結果になるでしょう。これがコントロールファイルをバックアップする手段として唯一サポートされた方法です。(oraback.sh も含めて)人によっては、手作業でもコントロールファイルをバックアップしています。"正式な"コピーよりも新しい手作業によるコピーがある場合、先にそれを試して下さい。それがうまく動作しなかった場合、backup control file to filename コマンドによって生成されたバックアップを使用して下さい。バックアップされたコントロールファイルを使用する場合、configORACLE_SID.ora 内の controo_files の後にリストされている場所に同じ名前でそれをコピーして下さい。
control_files = (/db/Oracle/a/oradata/crash/control01.ctl, /db/Oracle/b/oradata/crash/control02.ctl, /db/Oracle/c/oradata/crash/control03.ctl)
繰り返します。ここで使用するバックアップされたコントロールファイルは、このインスタンス内の最も新しいデータベースファイルよりもさらに新しくなければいけません。そうでないとオラクルが不平を言います。
Startup mount
そのコントロールファイルが正当なものかどうか、そして全ての正しい場所にコピーされたかどうかを調べるには、startup に mount オプションを付けて実行してみます(これはステップ 1 と同じコマンドです)。 これを行うには、マウントして閉じられたデータベース上で以下のコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > startup mount; Statement processed. SVRMGR > quit
読み取り専用のテーブルスペースをオフラインにする
オラクルは recover database using backup control file の実行中に読み取り専用のデータファイルをオンラインにすることを許可していません。そのため読み取り専用のデータファイルが存在する場合には、それらをオフラインにします。読み取り専用のデータファイルが存在するかどうかを調べるには、マウントして閉じられたデータベース上で以下のコマンドを実行して下さい。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select enabled, name from v$data file; Statement processed. SVRMGR > quit
それぞれの読み取り専用データファイル毎に、以下のコマンドを実行して下さい。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > alter database data file 'filename' offline; Statement processed. SVRMGR > quit
このステップは、ステップ 2 〜 7 に失敗した場合にのみ必要です。
バックアップからコントロールファイルをリストアした後、それらを使って recover database を実行してみます。
通常の recover database を試みる
backup control file を用いるデータベースの復旧には alter database open resetlogs オプションが必要なため、先に通常の recover database を試みることによる損害はありません。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > recover database;
backup control file オプションが必要であれば、オラクルが不平を言ってきます:
SVRMGR > recover database ORA-00283: Recover session cancelled due to errors ... ORA-01207: file is more recent than controlfile - old controlfile
recover database が正常に動作した場合、ステップ 10 に進んで下さい。正常に動作しなかった場合、"recover database using backup control file" を試みます。
recover database using backup control file を試みる
マウントして閉じられたデータベース上で以下のコマンドを使用して、データベースの復旧を試みます。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > recover database using backup controlfile
これが正常に動作した場合、出力は図 E のようになるでしょう。
ORA-00279: change 38666 generated at 03/14/98 21:19:05 needed for thread 1 ORA-00289: suggestion : /db/Oracle/admin/crash/arch/arch.log1_494.dbf ORA-00280: change 38666 for thread 1 is in sequence #494
オラクルが不平を言ってきた場合、データファイルが失われているか壊れている可能性があります。もうしそうなら、ステップ 4 と 5 に戻って下さい。失われたか壊れているデータファイルをリストアした後、このステップに戻り、recover database を再実行して下さい。
recover database の実行時、まれにオラクルがコントロールファイルよりもデータファイルが新しいという不平を言い、苦境に立たされる場合があります。これを回避する唯一の方法は、コントロールファイルのバックアップよりも古いデータファイルを使用することです。その古いデータファイルが失っている変更はメディアリカバリによってロールフォワードされるでしょう。
全てのアーカイブ redo log を適用する
オラクルはリストアされた中で最も古いデータファイル以降の全てのアーカイブ redo log を要求してくるでしょう。例えばデータファイルをリストアしたバックアップが 3 日前のものであれば、オラクルはそれ以降に作成された全てのアーカイブ redo log を必要とします。さらに、最初に求められるログファイルは必要なログファイルの内の最も古いものです。
アーカイブ redo log を適用する最も効率的な方法は、最初のログファイルの場所として指定したディレクトリに全てのログファイルを未圧縮の状態で置いておくことです。この場合、プロンプトから単純に auto を入力して下さい。そうでない場合、必要でなくなったファイルを圧縮するか削除しながら、要求される度に別の場所を指定するかエンターを押して下さい。
オンライン redo log が利用可能なら適用する
可能ならオラクルは全てのアーカイブ redo log とオンライン redo log を自動的に適用し、"Media recovery complete." と言います。
しかしながらオラクルは、全てのアーカイブ redo log を適用した後にオンライン redo log を求めてくるかもしれません。その場合オラクルは、利用可能な最新のアーカイブ redo log よりも大きい番号のアーカイブ redo log を求めるプロンプトを出してきます。これはオラクルがオンライン redo log を探しているということを意味しています。そのプロンプトに対して、あなたが保持しているオンライン redo log の名前を入力してみて下さい。不運にも間違った名前を与えてしまった場合、recover database using backup controlfile コマンドを最初からやり直すことになります。
例えば、以下の3つのオンライン redo log を保持していると仮定します。
/oracle/data/redolog01.dbf /oracle/data/redolog02.dbf /oracle/data/redolog03.dbf
あなたが保持しているアーカイブ redo log よりも大きい番号のアーカイブ redo log を求められたら、上記のファイルのひとつ(例 /oracle/data/redolog01.dbf )を指示して下さい。そのファイルに求められているリカバリスレッドが含まれていなければ、以下のようなメッセージが出力されます。
ORA-00310: archived log contains sequence 2; sequence 3 required ORA-00334: archive log: '/oracle/data/redolog01.dbf'
オラクルはあなたにもう一度やり直すことを要求し、recover database を中止します。再び同じプロンプトが表示されたら、別のファイル(/oracle/data/redolog02.dbf)を指示して下さい。リカバリスレッドが含まれていれば以下のようなメッセージが出力されます。
Log applied. Media recovery complete.
あなたが保持していないログを求めるプロンプトに対して全てのオンライン redo log を試みた後、cancel とだけ入力して下さい。
Alter database open resetlogs
メディアリカバリが完了したら、データベースをオープンします。最初の方で述べたように、backup control file を使って recover database を行った場合には resetlogs オプションを付けてデータベースをオープンしなければいけません。それには以下のように入力します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > alter database open resetlogs; SVRMGR > quit
resetlogs オプションを付けて recover database を実行した後、すぐにバックアップを取って下さい! データベースをシャットダウンした後のコールドバックアップが最良ですが、どうしても必要な場合はホットバックアップを実行して下さい。ただしその場合には次のようなリスクがあることを認識して下さい。
データベースのオープンに失敗した場合、ステップ 1 に戻って最初からやり直して下さい。
データベースのオープンに成功した場合、すぐにデータベース全体のバックアップ(コールドバックアップが望ましい)を実行して下さい。おめでとうございます! 完了です!
startup mount が正常に動作した場合、これはあなたが実行するべき第二ステップに過ぎません。データベースのマウントはコントロールファイルの存在と一貫性しかチェックしません。これが正常に動作した場合、データベースをオープンすることが次のステップになります。これにより、全てのデータファイル、オンライン redo log 、ロールバックセグメントの一貫性がチェックされます。データベースをオープンするには、マウントして閉じられたデータベース上で以下のコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > alter database open; SVRMGR > quit
データベースのオープンに成功した場合、オラクルは単純に "Statement processed." と出力します。これが最初の open database の試みであり、なおかつ全てのデータファイルとロールバックセグメントとがオフラインになっていない場合、完了です!
ステップ 26 か 28 (ロググループの破損)からこのステップへ来ている場合、ステップ 23 に戻り、データベース全体を復旧して下さい。
データベースのオープンに成功した場合、ステップ 15 に進んで下さい。
データベースのオープンに失敗 した場合、その状況によって出力は様々です。以下は起こり得る問題と、その問題が発生した場合にどのようなエラーが出力されるかの一覧です。
データファイルが失われている
ORA-01157: cannot identify data file 1 - file not found ORA-01110: data file 1: '/db/Oracle/a/oradata/crash/system01.dbf'
データファイルが壊れている
データファイルが壊れている場合、多くの種類のエラーを生成し得ます。例えばデータファイルが失われた場合と似た次のようなメッセージかもしれません。
ORA-01157: cannot identify data file 1 - file not found ORA-01110: data file 1: '/db/Oracle/a/oradata/crash/system01.dbf'
オラクルが完全に混乱した場合:
ORA-00600: internal error code, arguments: [kfhcfh1_01], [0], [], [], [], [], [], []
壊れたデータファイルは "failed verification check" エラーも発生し得ます:
ORA-01122: database file 1 failed verification check ORA-01110: data file 1: '/db/Oracle/a/oradata/crash/system01.dbf' ORA-01200: actual file size of 1279 is smaller than correct size of 40960 blocks
データファイルが壊れている場合にオラクルが出力する可能性のあるエラーの内、これらはほんの数種類の例でしかありません。
いずれかのオンラインロググループ内のメンバーが失われている
redo log がミラーリングされており、オンライン redo log のひとつまたは複数のコピーは失われているが、少なくともひとつは正常に残っている場合、オラクルは端末にエラーを表示せずにデータベースをオープンします。唯一のエラーは alert log に出力される以下のようなメッセージです。
Errors in file /db/Oracle/admin/crash/bdump/crash_lgwr_10302.trc: ORA-00313: open failed for members of log group 2 of thread 1
All members of any online log group are corrupted
しかしながら何れかのロググループ内の全てのメンバーが壊れている場合、オラクルは不平を言ってデータベースをオープンしません。この時のエラーは以下のようなものです。
ORA-00327: log 2 of thread 1, physical size less than needed ORA-00312: online log 2 thread 1: '/db/Oracle/b/oradata/crash/redocrash02.log' ORA-00312: online log 2 thread 1: '/db/Oracle/a/oradata/crash/redocrash03.log'
何れかのオンラインロググループ内の全てのメンバーが失われている
ひとつのオンラインロググループ内の全てのメンバーが失われているにも、同じような問題が発生します。オラクルは不平を言ってデータベースをオープンしません。この時のエラーは以下のようなものです。
ORA-00313: open failed for members of log group 2 of thread 1 ORA-00312: online log 2 thread 1: '/db/Oracle/b/oradata/crash/redocrash02.log' ORA-00312: online log 2 thread 1: '/db/Oracle/a/oradata/crash/redocrash03.log'
ロールバックセグメントが破損している
ロールバックセグメントが破損している時のエラーは次のような内容です。
ORA-01545: rollback segment 'USERS_RS' specified not available
全てのロールバックセグメントが利用可能でない限り、データベースはオープン出来ません。
破損したデータファイル
実際のところ、破損したデータファイルの復旧は非常に簡単です。これは良い事です。なぜならこの問題は他の問題よりも頻繁に起こるからです。ミラーリングされたオンライン redo log やコントロールファイルとは異なり、各データファイルは唯ひとつのコピーしか存在しないことを思い出して下さい。つまり統計的に言って、ミラーリングされたロググループの全てのコピーやミラーリングされたコントロールファイルの全てのコピーを失うよりも、ひとつのデータファイルを失うことの方が可能性が高いということです。
オラクルは、データベースの一部に対し、その他の部分がオンラインになっている間でも復旧させる能力を持っています。とは言えこれは、部分的に機能するデータベースがあなたの環境においてユーザーに有用である場合にのみ助けになります。つまり、全てのテーブルが有効でないと意味のないデータベースでは、この特徴から利益を得ることは出来ません。しかしながら破損したファイルの復旧中にユーザーがデータベースの一部を使う事ができれば、停止中でも少なくとも一部を機能させることで体面を保つ手助けにはなるでしょう。
リカバリに関する限りにおいては、3 種類のデータファイルが存在します。
破損したロググループ
ひとつのロググループ内の全てのメンバーが破損している場合、かなり高い確率でデータが損失しています。破損したロググループの状態とそれを修正する試みの結果とによっては、データベース全体をリストアしなければならないかもしれません。これは壊れたレコードのように見えるかもしれません。これこそが、なぜロググループをミラーリングする事が非常に重要なのかという理由です。
ロググループが破損していることを示すエラーの場合、すぐにステップ 17 へ進むのもひとつの選択肢です。しかしながら他にも破損した部分がないかどうかを確認するのも、もうひとつの選択肢てす。その場合には以下の注意を読んでから次のステップに進んで下さい。
破損したロールバックセグメント
オラクルはロールバックセグメントが利用可能かどうかを確認する前にそのロールバックセグメントを含むデータファイルをオープンしなければならないため、このエラーはデータファイルがオフラインでない限り発生しません。ロールバックセグメントを含む含まないに関わらず、破損したデータファイルに遭遇した場合、オラクルはそのデータファイルに不平を言い、データベースのオープンを中止します。
ロールバックセグメント はロールバック 情報を格納する特殊なテーブルスペースだという事を思い出して下さい。ロールバック情報はコミットしていないトランザクションをアンドゥ(またはロールバック)するために必要です。クラッシュしたデータベースはたいていコミットされていないトランザクションを含んでいるため、破損したロールバックセグメントを持つデータベースのリカバリは少々扱い難い問題です。前述したように、破損したデータファイルはオフラインになっていますが、オラクルはロールバックセグメント無しではデータベースをオープン出来ません。
ロールバックセグメントが存在しないのだとオラクルに思い込ませることが、この問題を解決する方法です。これによってデータベースをオンラインに出来ます。しかしながらロールバックされる必要のあるトランザクションは存在するでしょうし、それらはロールバックセグメントを要求するでしょう。しかしオラクルはロールバックセグメントが利用できないと思っているので、ロールバックは発生しません。すなわちこれは、データベースはオンラインになったものの、その一部は利用可能ではないという事を意味しています。
例えば、テーブルスペース USERS 内に data1 というテーブルを作成していたと仮定します。テーブルスペース USERS は、データファイル /db/oracle/a/oradata/crash/users01.dbf を含んでいます。不運にも、トランザクションがコミットされる前にデータベースがクラッシュし、そのトランザクションのためのロールバックセグメントを含むデータファイルが破損しました。私達はこのデータベースを復旧する過程において、そのデータファイルをオフラインにし、オラクルにそれが含まれるロールバックセグメントは必要ないと思い込ませ、データベースをオープンします。ここで select * from data1 を実行すると、図 F のようなエラーを受け取ります。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select * from data1; C1 ------------ ORA-00376: file 7 cannot be read at this time ORA-01110: datafile 7: '/db/oracle/a/oradata/crash/users01.dbf'
このエラーの原因は、オラクルが /db/oracle/a/oradata/crash/users01.dbf 内のコミットされていないトランザクションがロールバックされたかどうかを知らないためです。このデータベースを完全に機能させるためには、破損したデータファイルを復旧し、ロールバックセグメントをオンラインにしなければいけません。
このようにロールバックセグメント無しでデータベースをオンラインにした場合、データベースはオンラインになるかもしれませんが、恐らく完全には機能しないということに注意して下さい。
ロールバックセグメントが破損していることを示すエラーの場合、ステップ 18 に進んで下さい。
ここから先に進む前に
あるファイルでエラーに遭遇すると、オラクルはすぐにデータベースのオープンを中止することを思い出して下さい。当然ながらこれは、他のファイルも破損しているかもしれないということを意味しています。ひとつでも破損したデータファイルが存在するのなら、その他に破損したファイルがないかどうかを確認する良い機会です。
これを行う手順の詳細はステッ 5 に書かれています。
全ての破損したファイル名が分かった後、次のセクションに進んで下さい。
メディアリカバリはどのように動作するのか
何れかのファイルをバックアップからリストアした場合、svrmgr の recover コマンドが必要になるでしょう。このコマンドは、バックアップが取られた時以降に発生した全てのトランザクションを再適用するために、アーカイブ redo log とオンライン redo log とを使用します。データベース・テーブルスペース・データファイルを、それぞれ recover database・recover tablespace テーブルスペース名・recover data file データファイル名の各コマンドを実行することで復旧することが出来ます。これらのコマンドは svrmgr のシェル内で実行します。
$ svrmgrl SVRMGR > connect internal SVRMGR > startup mount SVRMGR > recover datafile '/db/Oracle/a/oradata/crash/datafile01.dbf'
これらのコマンドは、古いバージョンのデータファイルのリストアと、故障した時点までロールフォワードするための redo log の再適用とを可能にしています。例えば水曜日の夜にデータファイルのバックアップを取り、木曜日の夕方にそのデータファイルが破損した場合、水曜日の夜のバックアップからデータファイルをリストアします。当然、水曜の夜以降にも多くのトランザクションが発生し、リストアしたデータファイルへの変更を行っているでしょう。recover [database |tablespace |data file ] コマンドの実行は、リストアしたデータファイルに対してこれらのトランザクションを再適用し、木曜日の夕方の状態へとロールフォワードします。
このリカバリは多くの方法で動作させることが出来ます。recover コマンドを受け取った後、オラクルは最初のアーカイブ redo log の名前と場所とを求めるプロンプトを表示します。そのログとそれ以降に作られた全てのログがオンラインで未圧縮かつ元の場所に置かれている場合、AUTO と入力します。これはオラクルに対し、必要な全てのファイルがオンラインであると仮定するように指示していることになります。その結果オラクルは、必要な各ログを使って自動的にロールフォワードを行うことが出来ます。
これを行うには、オラクルが必要とする全てのファイルがオンラインでなければいけません。まず、オラクルが必要とする最初のファイルとなる、最も古いファイルの名前を取得します。そのファイル名は recover コマンドを実行した後、すぐに表示されます。
ORA-00279: change 18499 generated at 02/21/98 11:49:56 needed for thread 1
ORA-00289: suggestion : /db/Oracle/admin/crash/arch/arch.log1_481.dbf
ORA-00280: change 18499 for thread 1 is in sequence #481
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
上の例では、オラクルが必要とする最初のファイルは /db/Oracle/admin/crash/arch/arch.log1_481.dbf になります。このファイルがオンラインであり、圧縮されたり削除されたりしていない事を確認して下さい。削除されている場合はバックアップからリストアして下さい。圧縮されている場合は、そのファイルと、そのディレクトリ内にあるそのファイルより新しい全てのアーカイブ redo log とを展開して下さい。これはオラクルがメディアリカバリを完了するためにそれら全てを必要とするかもしれないためです。これらのファイルを展開するための十分な空き領域を作るために、古いアーカイブ redo log を削除する必要があるかもしれません。オラクルが要求したものより新しい全てのアーカイブ redo log をリストア・展開した後、"Specify log" のプロンプトに AUTO と入力して下さい。
全てのアーカイブ redo log を展開するための十分な空き領域がない場合、少し創造力が要求されるかもしれません。出来るだけ多くを展開し、次のファイルを示すように毎回エンターを入力します。(エンターの入力は、そのファイルが使用可能であることをオラクルに伝えます。そのファイルが利用出来ないことが分かった場合、オラクルは再び同じファイルに対するプロンプトを出します) ひとつのアーカイブログが終了したらそれを圧縮し、新しいログを展開します。(当然ながら二番目のウィンドウが必要です。三番目のウィンドウを開いても問題ありません!)
オラクルは使用不可能なアーカイブ redo log を求めてくるかもしれません。これはそのアーカイブ redo log またはオンライン redo log が破損していることを意味しています。そのファイルを置くこともリストアすることも出来ない場合、CANCEL と入力して下さい。
メディアリカバリに関するより詳細な情報は、オラクルのドキュメントにて利用可能です。
データベースのオープンに失敗した場合、前述の注意を読んだ後にステップ 11 に進んで下さい。データベースのオープンに成功した場合、ステップ 15 に進んで下さい。
破損したファイルが SYSTEM テーブルスペースの一部であった場合、オフラインでのリカバリが必要です。その他の全ての失われたデータファイルは、データベースがオンラインの状態でも復旧できます。残念ながら、オラクルは単にデータファイルが失われているとしか言わず、そのデータファイルの種類 は言いません。幸運にも、たとえオラクルがダウンしていたとしても、どのファイルが SYSTEM テーブルスペースに属しているかを特定する簡単な方法があります。(ロールバックセグメントを含むデータファイルを探すのはこれよりも少し困難ですが、それでも可能ではあります。) どのデータファイルが SYSTEM テーブルスペースに含まれるのかを探すには、マウントして閉じられたデータベース上で以下のコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select name from v$datafile where status = 'SYSTEM' ; NAME -------------------------------------------------------------------------------- /db/oracle/a/oradata/crash/system01.dbf 1 row selected.
この例では、SYSYTEM テーブルスペースのメンバーである唯一のファイルが /db/Oracle/a/oradata/crash/system01.dbf であることを示しています。設定によっては SYSTEM テーブルスペースに複数のデータファイルが存在するかもしれません。
破損したデータファイルの何れかが SYSYTEM テーブルスペースのメンバーだった場合、ステップ 12 に進んで下さい。何れも SYSTEM テーブルスペースのメンバーではなかった場合、ステップ 13 に進んで下さい。
他のテーブルスペースとは異なり、SYSTEM テーブルスペースはデータベースをオープンするために使用可能でなければいけません。従って、SYSTEM テーブルスペースの何れかのメンバーが破損した場合、まずはそれらをリストアしなければいけません。これを実行する前に、データベースがオープンされていないことを確認して下さい(マウントはされていても大丈夫です)。これを確認するには、マウントして閉じられたデータベース上で以下のコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select status from v$instance; STATUS ------- MOUNTED 1 row selected.
(上の例は、このインスタンスがマウントはされているがオープンはされていない事を示しています。)
データベースのオープンに失敗した場合、破損しているファイルを、利用可能な最新のバックアップからリストアして下さい。SYSTEM テーブルスペースに含まれる全ての破損したファイルをリストアした後、マウントして閉じられたデータベース上で以下のコマンドを実行して下さい。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > recover tablespace system; SVRMGR > media recovery complete
このコマンドが完了すれば、SYSTEM テーブルスペースは障害が発生した時点まで復旧しているでしょう。
これが成功し、その他のファイルが破損していない場合、ステップ 10 に戻って下さい。recover tablespace コマンドに関するより多くの情報を得るには、ステップ 10 の最後にある "メディアリカバリはどのように動作するのか" を参照して下さい。他にも復旧しなければならないデータファイルがある場合、ステップ 13 に進んで下さい。
ここまでに私達はデータベースをマウントしています。これはコントロールファイルが正常であることを証明しています。ひとつまたは複数のコントロールファイルが破損している場合には多少の努力が必要だったかもしれませんが、それでもうまく行きました。さらに私達は、たとえリストアやリカバリが必要であったとしても、 SYSTEM テーブルスペースが正常である事も確認しました。この手順の残りの大部分は、なるべく早くデータベースをオンラインに出来るように、データベースの破損した部分を無効にすることに集中しています。一度でもデータベースのオープンに成功すれば、消去法によって全ての破損したデータファイルを識別できます。その後、それらは簡単にリストア出来ます。
SYSTEM テーブルスペースの一部ではないデータファイルが破損している場合、ステップ 14 に進んで下さい。破損したデータファイルがこれ以上存在しない場合、ステップ 17 に進んで下さい。
破損した非システムデータファイルを持つデータベースをオープンするには、そのデータファイルをオフラインにします。(オフラインにされるデータファイルがロールバックセグメントを含むテーブルスペースの一部の場合、もうひとつ別のステップが必要です。しかしここではそれに出くわしてから考える事にします。)
インスタンスが ARCHIVELOG モードで運用されている場合、単にそのデータファイルをオフラインにして下さい。そのデータファイルはインスタンスをオンラインにした後でリストアや復旧を行う事が出来ます。これを実行するには以下のコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > alter database datafile 'filename' offline;
インスタンスが NOARCHIVELOG モードで運用されている場合、これは別の問題です。この場合オラクルは、メディアリカバリ無しにデータファイルをオンラインに戻すことが出来ないことを知っているため、データファイルをオフラインにすることを許しません。ARCHIVELOG モードでなければメディアリカバリは有り得ません。唯一オラクルが許可していることは、そのデータファイルを完全に消すことだけです。つまりこれは、このファイルを含むテーブルスペースはゼロから再構築されなければならないという事を意味しています。これは、なぜ製品のインスタンスは NOARCHIVELOG モードで運用するべきではないのかという数多くの理由のひとつです。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > alter database datafile 'filename' offline drop;
何れかの破損したファイルをオフラインにした後、ステップ 10 に戻り、再びデータベースのオープンを試みて下さい。
このステップはデータベースがオープンされた後にのみ実行して下さい。
このステップは非常に簡単な質問だけです!
全てのデータファイルをオフラインにすることなくデータベースをオープンできた場合、ステップ 29 に進んで下さい。データベースをオープンするためにいくつかのデータファイルをオフラインにしている場合、ステップ 16 に進んで下さい。もし確信を持てなければ、ステップ 16 に進んで下さい。
最初に、どのデータファイルがオフラインにされたかを探します。これを行うには、以下のコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select name from v$datafile where status = 'OFFLINE' ; NAME ------------------ /db/oracle/a/oradata/crash/temp01.dbf /db/oracle/a/oradata/crash/tools01.dbf /db/oracle/a/oradata/crash/users01.dbf
破損したデータファイルをリストアする
リストアする必要のあるデータファイルの名前が判明したら、それらを最新のバックアップからリストアします。それらをリストアした後、オラクルでは 3 種類の異なる方法でリカバリする事が出来ます。各方法は複雑さや自由度の点で大きく異なります。以下の3つのメディアリカバリの方法を良く調べて、あなたにとって最良のひとつを選択して下さい。
データファイルのリカバリ
復旧するデータファイルの数が少ない場合には、これが最も簡単な選択肢でしょう。各ファイルをリストアするたびに、そのファイルに対してrecover datafile コマンドを実行し、その後そのファイルをオンラインにして下さい。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > recover datafile 'datafile_name'; Statement processed. SVRMGR > alter database datafile 'datafile_name' online ; Statement processed.
この方法の不利な点は、各データファイル毎のメディアリカバリが少々時間を取ってしまうかもしれないという事です。単一のテーブルスペース内の複数のデータファイルを復旧する場合、これは恐らく時間の無駄です。
テーブルスペースのリカバリ
これは3つのうち最も難しい方法ですが、ひとつのテーブルスペース内にいくつかの破損したデータファイルが存在している場合には、先の方法よりも早く終わるかもしれません。破損したデータファイルを復旧している間に部分的にでもデータベースを機能させる事を強制され、かつ復旧するデータファイルが複数存在しているなら、恐らくこれが最良の選択肢です。
最初に全てのデータファイルの名前とそれらが属するテーブルスペースを探します。データベースはすでにオープンしているので、この作業は図 G のようなひとつのステップで実行出来ます。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select file_name, tablespace_name from dba_data_files; Statement processed. FILE_NAME TABLESPACE_NAME -------------------------------------------------------------------------------- ------------------------------ /db/oracle/a/oradata/crash/users01.dbf USERS /db/oracle/a/oradata/crash/tools01.dbf TOOLS /db/oracle/a/oradata/crash/temp01.dbf TEMP /db/oracle/a/oradata/crash/rbs01.dbf RBS /db/oracle/a/oradata/crash/system01.dbf SYSTEM /db/oracle/a/oradata/crash/test01.dbf TEST
この出力の唯一の問題は、非常に読み辛く、もし何百ものデータファイルがあれば読み取るのも不可能であろうという事です。これをより読み易くするためのひとつの方法は、図 H に示すようにコマンドを修正する事です。
$ svrmgrl <<EOF |sed 's/ */ /' |sort >/tmp/files.txt connect internal; select file_name, tablespace_name from dba_data_files; quit; EOF grep '^/' /tmp/files.txt /db/oracle/a/oradata/crash/rbs01.dbf RBS /db/oracle/a/oradata/crash/system01.dbf SYSTEM /db/oracle/a/oradata/crash/temp01.dbf TEMP /db/oracle/a/oradata/crash/test01.dbf TEST /db/oracle/a/oradata/crash/tools01.dbf TOOLS /db/oracle/a/oradata/crash/users01.dbf USERS
この方法ではファイルがアルファベット順にソートされており、必要なファイルを探すのが容易になっています。
全てのデータファイルをリストアし、それらのデータファイルを含む全てのテーブルスペースの名前が判明した後、それらのテーブルスペース毎に recover tablespace コマンドを実行して下さい。ただしそれを行う前に、図 I で示すように、それらのテーブルスペースをオフラインにしなければいけません。
$ svrmgrl
SVRMGR > connect internal;
Connected.
SVRMGR > alter tablespace tablespace_name1 offline;
Statement processed.
SVRMGR > recover tablespace tablespace_name1 ;
ORA-00279: change 18499 generated at 02/21/98 11:49:56 needed for thread 1
ORA-00289: suggestion : /db/Oracle/admin/crash/arch/arch.log1_481.dbf
ORA-00280: change 18499 for thread 1 is in sequence #481
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
Auto
Log applied
Media Recovery Complete
SVRMGR > alter tablespace tablespace_name1 online;
Statement processed.
SVRMGR > alter tablespace tablespace_name2 offline;
Statement processed.
SVRMGR > recover tablespace tablespace_name2 ;
ORA-00279: change 18499 generated at 02/21/98 11:49:56 needed for thread 1
ORA-00289: suggestion : /db/Oracle/admin/crash/arch/arch.log1_481.dbf
ORA-00280: change 18499 for thread 1 is in sequence #481
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
Auto
Log applied
Media Recovery Complete
SVRMGR > alter tablespace tablespace_name2 online;
Statement processed.
明らかにこの方法はかなり複雑です! 綺麗でも簡単でもありませんが、この方法はインスタンスが運用を続けている間に複数のテーブルスペースをリカバリする事を可能にします。部分的に稼動するデータベースでも利用者にとって価値があるのなら、この方法は最も良い選択でしょう。
データベースのリカバリ
実際のところこの方法が最も簡単です。しかしこれを実行するには、データベースをシャットダウンする必要があります。全てのファイルをリストアしてオフラインにした後、データベースをクローズして recover database コマンドを実行して下さい。
全てのファイルをリストアした後、図 J に示すようにコマンドを実行して下さい。
$ svrmgrl
SVRMGR > connect internal;
Connected.
SVRMGR > alter database close ;
Statement processed.
SVRMGR > recover database ;
ORA-00279: change 18499 generated at 02/21/98 11:49:56 needed for thread 1
ORA-00289: suggestion : /db/Oracle/admin/crash/arch/arch.log1_481.dbf
ORA-00280: change 18499 for thread 1 is in sequence #481
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
Auto
Log applied
Media Recovery Complete
SVRMGR > alter database open
Statement processed.
全てのテーブルスペースとデータファイルが適切な状態に戻っている事を確認するために、図 K に示すようにコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select name, status from v$datafile NAME STATUS -------------------------------------------------------------------------------- ------- /db/oracle/a/oradata/crash/system01.dbf SYSTEM /db/oracle/a/oradata/crash/rbs01.dbf ONLINE /db/oracle/a/oradata/crash/temp01.dbf ONLINE /db/oracle/a/oradata/crash/tools01.dbf ONLINE /db/oracle/a/oradata/crash/users01.dbf ONLINE /db/oracle/a/oradata/crash/test01.dbf ONLINE 6 rows selected. SVRMGR > select member, status from v$logfile NAME STATUS -------------------------------------------------------------------------------- ------- /db/oracle/a/oradata/crash/system01.dbf SYSTEM /db/oracle/a/oradata/crash/rbs01.dbf ONLINE /db/oracle/a/oradata/crash/temp01.dbf ONLINE /db/oracle/a/oradata/crash/tools01.dbf ONLINE /db/oracle/a/oradata/crash/users01.dbf ONLINE /db/oracle/a/oradata/crash/test01.dbf ONLINE 6 rows selected. SVRMGR > select * from v$controlfile; STATUS NAME ------- ------------------------------------------------------------------------ -------- /db/oracle/a/oradata/crash/control01.ctl /db/oracle/b/oradata/crash/control02.ctl /db/oracle/c/oradata/crash/control03.ctl 3 rows selected.
上の例は、全てのデータファイル、コントロールファイル、ログファイルが正常な状態であることを示しています。(ログファイルとコントロールファイルの場合、STATUS が無いことが正常な状態である事を表します。)
全てのオフラインにされていたデータファイルをリストアし復旧した後、ステップ 29 に進んで下さい。
ここまでで破損したロググループについて言及した場合、それはロググループの全てのメンバーが破損しているという事を意味していました。ミラーリングされたロググループの内、少なくともひとつのメンバーが正常であれば、オラクルはデータベースをオープンし、単に alert log にエラーメッセージを出力するだけです。しかしながらロググループの全てのメンバーが破損している場合、データベースはオープンされず、以下のようなエラーが出力されます。
ORA-00313: open failed for members of log group 2 of thread 1 ORA-00312: online log 2 thread 1: '/db/Oracle/b/oradata/crash/redocrash02.log' ORA-00312: online log 2 thread 1: '/db/Oracle/a/oradata/crash/redocrash03.log'
このようなエラーがでなかった場合、破損したロググループはありません。ステップ 18 に進んで下さい。
最初に特定しなければならない事は、破損したロググループの状態です。三つの状態、current、active、inactive が有り得ます。破損したロググループの状態を特定するには、マウントして閉じられたデータベース上で以下のコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select group#, status from v$log;
出力は以下のような内容でしょう。
GROUP# STATUS ---------- ---------------- 1 INACTIVE 2 CURRENT 3 ACTIVE 3 rows selected.
上記の例ではロググループ 1 が inactive、グループ 2 が current、グループ 3 が active である事を示しています。以下、これらの状態とそれぞれがリカバリにどのような影響を与えるかの説明です。
Current
current のロググループは、障害が発生したときにオラクルが書込みを行っていたロググループです。サーバーがオンラインになりログスイッチが発生するまで、これは使用中(active)であるとしてリストされます。
Active
active のロググループは、通常オラクルが書込みを終了したばかりのロググループです。しかしながら、チェックポイントが発生するまでこのグループはメディアリカバリのために必要です。ログスイッチが常にチェックポイントを発生させるため、実際のところ active という状態は非常に稀です。実際、(システムクラッシュ以外で)これを見る唯一の方法は、チェックポイントの発生中に上記のコマンドを実行することだけです。(適切にチューニングされたデータベースでは、これは非常に短い時間です)
Inactive
inactive のロググループは、オラクルが使用していないロググループです。
次に取るべき行動を決めるために、まずログファイルが破損しているロググループの数を取得しました。上記のエラーの例では、ロググループ 2 のメンバーを開くことに失敗している事が読み取れます。select * from v$log の結果からこの番号を参照して下さい。上記の例の場合、データベースがクラッシュした時のロググループ 2 は current でした。
破損したロググループが current の場合、ステップ 22 に進んで下さい。active の場合、ステップ 25 に進んで下さい。inactive の場合、ステップ 27 に進んで下さい。
ロールバックセグメントが破損している場合、オラクルはデータベースをオープンする時に不平を言います。その時のエラーは以下のような内容です。
ORA-01545: rollback segment 'USERS_RS' specified not available Cannot open database if all rollback segments are not available.
ステップ 10 の破損したロールバックセグメントに関する注意事項をまだ読んでいなければ、今すぐ読んで下さい。
データベースのオープン時に上のエラーが出力された場合、ステップ 19 に進んで下さい。エラーが出力されなかった場合、ステップ 10 に進んで下さい。
破損したロールバックセグメント独特の性質により、ここでは二つの選択肢があります。第一の選択肢は、早めにデータベースをオープンしますが、比較的長時間に渡って部分的にしか機能しない状態になります。第二の選択肢は、データベースのオープンまでには少々時間が掛かりますが、一旦オープンしてしまえばそのロールバックセグメントのために必要とされていたデータファイルはもう必要なくなります。部分的にしか機能しなくてもすぐにデータベースをオープンする事と、全てのロールバックセグメントが使用可能になるまでデータベースをオープンしない事、どちらがより重要ですか? 後者の方が合理的な選択と言えますが、環境によっては前者の方がより適切かもしれません。
データベースが部分的にしか機能しなくても、出来るだけ早くオープンする必要がある場合、ステップ 21 に進んで下さい。データベースのオープン前に確実に全てのロールバックセグメントを使用可能にする事の方が重要な場合、ステップ 20 に進んで下さい。
このステップはステップ 19 でここを選んだ場合にのみ必要です。
まず最初に特定しなければならないのは、破損したロールバックセグメントが含まれるテーブルスペースはどれなのかという事です。不運にも、この情報を含むような決まったビューは存在しません。これは、常識と推論とによってそれを探さなければならないという事を意味しています。データファイルがオフラインでない限りこのエラーは出力されないという事を思い出して下さい。オフラインになっているファイルの完全なリストを得るには、マウントして閉じられたデータベース上で以下のコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select TS#, name from v$datafile where status = 'OFFLINE' ; NAME -------------------------------------------------------------------------------- 5 /db/oracle/a/oradata/crash/test01.dbf 1 row selected.
次に、このデータファイルを含むテーブルスペースの名前を探します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select name from v$tablespace where TS# = '5' ; NAME -------------------------------------------------------------------------------- TEST 1 row selected.
これは簡単すぎました!
明らかに上の例は簡単です。オフラインになっているデータファイルはひとつしかありません。それが含まれるテーブルスペースを探すのはとても簡単です。もしも複数のデータファイルを含む複数のテーブルスペースが存在した場合、どうしますか? どうすればロールバックセグメントの含まれるデータファイルを知る事が出来るのでしょう? 残念ながらデータベースをクローズしている間にそれを確認する方法はありません。そのため、ロールバックセグメントを含んでいることが簡単に分かる名前を持つ専用のテーブルスペースを作成することはとても有効です。データファイルに同じような名前を付けることも有効です。例えば ROLLBACK_DATA という名前でテーブルスペースを作成し、そのデータファイルには rollback01.dbf、rollback02.dbf といった名前を付けます。このようにすれば、どのファイルがロールバック情報を持っているのかを、誰でも正確に知る事が出来るでしょう。
このステップの残りは簡単です。オフラインにされている全てのファイルをリストアし、それらをロールフォワードするするために recover data file コマンドまたは recover tablespace コマンドを使用して下さい。破損したデータファイルがひとつか二つだけの場合は recover data file コマンドを使用した方が早いでしょう。破損したファイルがそれより多い場合、特にそれらがひとつのテーブルスペースに含まれている場合、恐らく recover tablespace コマンドが最も簡単でしょう。どちらの方法でもうまく行きます。
ロールバックセグメントを含む全てのデータファイルのリストアと復旧とが完了した後、ステップ 10 に戻り、再度データベースのオープンを試みて下さい。
このステップはステップ 19 でここを選んだ場合にのみ必要です。
破損したロールバックセグメントを含んだままデータベースをオープンするための、より早い方法が存在します。オラクルにロールバックセグメントを知らせるために、initORACLE_SID.ora ファイルに以下のような行が追加されています。
rollback_segments = (r01,r02,r03,r04,users_rs)
(initORACLE_SID.ora ファイルは通常 $ORACLE_HOME/dbs にあります。) 前述のエラーの例ではロールバックセグメント USERS_RS が使用不能である事が分かるので、単純にこの行からその部分を削除します。もちろん、元の行をコメントアウトしてコピーする方が賢明です。最初にオラクルを完全にシャットダウンして下さい。(これはデータベースのアンマウントも含みます。) 次に initORACLE_SID.ora ファイルのロールバックセグメントの行をコピーし、コメントアウトします。
#rollback_segments = (r01,r02,r03,r04,users_rs) rollback_segments = (r01,r02,r03,r04)
initORACLE_SID.ora への変更を行ったら、データベースをマウントするためにステップ 1 に戻って下さい。
このステップはステップ 17 で指示された場合にのみ行います。そうでなければすぐにステップ 17 に戻って下さい。
current のオンラインロググループが破損している場合、データベースのオープン時に以下のようなメッセージが出力されるでしょう。
ORA-00313: open failed for members of log group 2 of thread 1 ORA-00312: online log 2 thread 1: '/db/Oracle/b/oradata/crash/redocrash02.log' ORA-00312: online log 2 thread 1: '/db/Oracle/a/oradata/crash/redocrash03.log'
上記の例では select group#, status from v$log の結果、障害時にロググループ 2 が CURRENT であったことを示しています。
これは明らかにデータ損失が発生しているため、最も酷い障害のひとつと言えます。と言うのも、たとえ完全に機能するデータベースでも、再起動する場合には current のオンラインログは必要とされるからです。現在使用中のコントロールファイルは current のオンラインログを知っており、それを使おうとします。これを回避する唯一の方法は、古いバージョンのコントロールファイルをリストアする事ですが、残念ながらコントロールファイルだけをリストアする事は出来ません。なぜなら、データファイルはコントロールファイルよりも新しくなければならないためです。残された唯一の選択肢は、データベース全体をリストアする事です。
データベース全体をリストアするために、ステップ 23 に進んで下さい。
警告! このステップを実行する理由は二つしかありません。ひとつ目はステップ 22 で指示された場合です。もうひとつは、ステップ 26 か 28 を実行した後でもデータベースのオープンに失敗した場合です。このステップはリカバリの中でも最も過激な方法であり、確実に必要な場合以外には実行するべきではありません。
コントロールファイルを確認(または再構築、リストア)し、さらに current のオンラインロググループの全てのメンバーが破損している事を確かめた後にのみ、このステップを実行して下さい。このステップは比較的簡単です。単純に全てのデータファイルの名前と場所とを特定し、それらを最新のバックアップからリストアします。
警告! データファイルだけをリストアし、コントロールファイルはリストアしないで下さい。ステップ 9 でそうするように指示されたのではない限り、コントロールファイルをリストアしたり上書きしたりしてはいけません!
全てのデータファイルの名前を特定するためには、マウントして閉じられたデータベース上で以下のコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select name from v$datafile ;
全てのデータファイルをリストアした後、ステップ 24 に進んで下さい。
警告! このステップはステップ 23 で指示された場合にのみ行って下さい。これは必要な場合にのみ実行するべき、もうひとつの過激なステップです!
このコマンドはオンライン redo log の全ての内容をクリアした後にデータベースをオープンします。このステップをやり直す方法はありませんので、ここでオンライン redo log をコピーしておくのは良い考えです。全てのログファイルの名前を見つけるには、マウントして閉じられたデータベース上で以下のコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select member from v$logfile ;
"やり直す"という選択肢を作るために、各ファイルを filename.bak へとコピーします。
オンライン redo log のコピーを取った後、マウントして閉じられたデータベース上で以下のコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > alter database open resetlogs ; Statement processed.
データベースがオープン出来た場合、おめでとうございます、完了です!
すぐに データベースのバックアップ(データベースをシャットダウンした状態の方が望ましい)を行って下さい。その理由は、オラクルが redo log を使ったロール処理をこの時点を通しては行えないためです。open resetlogs が実行された後に作られたログを使ってデータベースを回復するために、open resetlogs コマンドを実行した後、完全なバックアップを取らなければいけません。
バックアップに成功したら、完了です!
このステップはステップ 17 で指示された場合にのみ実行して下さい。そうでなければすぐにステップ 17 に戻って下さい。
ACTIVE のオンラインロググループが破損している場合、データベースのオープン時に以下のようなメッセージが出力されるでしょう。
ORA-00313: open failed for members of log group 2 of thread 1 ORA-00312: online log 2 thread 1: '/db/Oracle/b/oradata/crash/redocrash02.log' ORA-00312: online log 2 thread 1: '/db/Oracle/a/oradata/crash/redocrash03.log'
上の例では、select group#, status from v$log コマンドの結果、障害発生時にロググループ 2 が ACTIVE であったことを示していす。
ACTIVE のログもリカバリに必要とされる事を思い出して下さい。これがまだ必要とされる理由は、チェックポイントが全ての変更をメモリからディスクに書き込めていないためです。一旦チェックポイントが発生すれば、このログはもう必要ありません。
チェックポイントを実行するためにステップ 26 に進んで下さい。
ステップ 25 のシナリオから回復を試みる方法は、チェックポイントを実行する事です。これに成功した場合、データベースのオープンも成功するはずです。チェックポイントを実行するには、マウントして閉じられたデータベース上で以下のコマンドを実行します。
1 $ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > alter system checkpoint local ; Statement processed.
我慢して下さい。ACTIVE のロググループが存在しているということは、チェックポイントが最初の段階で長い時間を必要とするということです。チェックポイントが成功したか失敗したかをオラクルが出力するまで待って下さい。成功した場合、オラクルは単に "Statement processed." と出力します。失敗した場合、いくつかのエラーが出力されるでしょう。
チェックポイントを実行した後、たとえそれが失敗していたとしてもステップ 10 に戻り、データベースのオープンを試みて下さい。データベースのオープンに失敗した場合、ステップ 23 に戻り、データベース全体を復旧して下さい。
このステップはステップ 17 で指示された場合にのみ実行して下さい。そうでなければすぐにステップ 17 に戻って下さい。
INACTIVE のオンラインロググループが破損している場合、データベースのオープン時に以下のようなメッセージが出力されるでしょう。
ORA-00313: open failed for members of log group 2 of thread 1 ORA-00312: online log 2 thread 1: '/db/Oracle/b/oradata/crash/redocrash02.log' ORA-00312: online log 2 thread 1: '/db/Oracle/a/oradata/crash/redocrash03.log'
上の例では select group#, status from v$log コマンドの結果、故障時にロググループ 2 が INACTIVE であったことを示していす。
これは比較的簡単な作業のはずです。INACTIVE のログはオラクルに必要とされていません。必要とされていないのですから、単純に削除し、その場所に別のファイルを追加して下さい。
INACTIVE のロググループの削除と追加を行うために、ステップ 28 に進んで下さい。
このステップはステップ 27 で指示された場合にのみ実行して下さい。
これまでの全ての例では、破損したログループはグループ 2 でした。このグループを削除する前に、それを簡単に元に戻せるようにしておくべきです。全てのオリジナルの redo log の場所がまだ有効である事を確認して下さい。これを行うには、このロググループの全てのメンバーの名前を取得します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > select member from v$logfile where GROUP# = '2 ;
この例の場合、オラクルは以下の値を返しました。
/logs1redolog01.dbf /logs2redolog01.dbf /logs3redolog01.dbf
これらのファイルの場所がまだ有効である事を確認して下さい。ここでの例として、/logs3 が完全に壊れており、その内容を全て /logs4 に再配置しようとしていると仮定します。従ってロググループ 2 の将来のメンバーは、/logs1redolog01.dbf 、 logs2redolog01.db、そして /logs4redolog01.dbf となります。
ロググループ 2 を削除するため、マウントして閉じられたデータベース上で以下のコマンドを実行します。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > alter database drop logfile group 2; Statement processed.
このコマンドに成功した後、データベースにロググループを追加して下さい。これを行うには以下のコマンドを実行します(/logs3redolog01.dbf を /logs4redolog01.dbf に置き換え済みという事に注意して下さい)。
$ svrmgrl
SVRMGR > connect internal;
Connected.
SVRMGR > alter database add logfile group 2 ('/logs1redolog01.dbf', '/logs2redolog01.dbf',
'/logs4redolog01.dbf') size 500K ;
Statement processed.
このコマンドに成功した場合、ステップ 10 に戻り、データベースのオープンを試みて下さい。
ステップ 19 において、initORACLE_SID.ora ファイルからロールバックセグメントをコメントアウトするという選択肢がありました。その選択肢を選んでいる場合、このファイルの中身は以下のようになっているはずです。
#rollback_segments = (r01,r02,r03,r04,users_rs) rollback_segments = (r01,r02,r03,r04)
何れかのロールバックセグメントをオフラインにしている場合、ステップ 30 に進んで下さい。そうでない場合、すぐにデータベースのバックアップを行って下さい。完了です!
どのロールバックセグメントがオフラインになっているのかを確認するには、以下のコマンドを実行します。
SVRMGR > select segment_name from dba_rollback_segs where status = 'OFFLINE' ; SEGMENT_NAME ------------------------------ USERS_RS 1 rows selected.
これまでに全てのデータファイルと redo log ファイルは復旧しているはずなので、オフラインになっているロールバックセグメントをオンラインに戻すだけです。
$ svrmgrl SVRMGR > connect internal; Connected. SVRMGR > alter rollback segment users_rs online ; Statement processed.
これに成功した場合、initORACLE_SID.ora ファイル内のコメントアウトした行を元の状態に戻している事を確認して下さい。ステップ 29 の例では、元の行をコメントアウトし、そのコピーを変更するという方法を使っていました。initORACLE_SID.ora 内のその行を元の状態に戻して下さい。
rollback_segments = (r01,r02,r03,r04,users_rs)
このステップは、次回データベースをオープンした時にロールバックセグメント USERS_RS が使用される事を確実にします。
ここまで来れば完了です! 全てのデータファイル、コントロールファイル、ログファイルはオンラインのはずです。すぐにデータベース全体のバックアップを行って下さい。データベースを落とした状態でのコールドバックアップが望ましいですが、もしそれが無理なら、ホットバックアップを行って下さい。